Activité 2 : notion de serveur web
Qu'est-ce qu'un serveur web ?
Consulter la vidéo suivante pour en savoir davantage et répondez au questionnaire fourni (Activité 2) :
Qu'est-ce qu'un serveur web ?
Consulter la vidéo suivante pour en savoir davantage et répondez au questionnaire fourni (Activité 2) :
Dans la barre d'adresse de votre navigateur web vous trouverez, quand vous visitez un site, des choses du genre : "https://www.atrium-sud.fr/group/snt-384628/accueil". Nous aurons l'occasion de reparler du "http" et du "www.atrium-sud.fr" plus tard. La partie "/group/snt-384628/accueil" s'appelle une URL.
Une URL (Uniform Resource Locator) permet d'identifier une ressource (par exemple un fichier) sur un réseau.
L'URL indique « l'endroit » où se trouve une ressource sur un ordinateur. Un fichier peut se trouver dans un dossier qui peut lui-même se trouver dans un autre dossier... On parle d'une structure en arborescence, car elle ressemble à un arbre à l'envers :
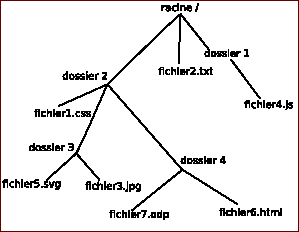
Fig. 1 : structure en arborescence
Comme vous pouvez le constater, la base de l'arbre s'appelle la racine de l'arborescence et se représente par un /
Pour indiquer la position d'un fichier (ou d'un dossier) dans l'arborescence, il existe 2 méthodes : indiquer un chemin absolu ou indiquer un chemin relatif.
Le chemin absolu doit indiquer « le chemin » depuis la racine. Par exemple l'URL du fichier fichier3.jpg sera :
/dossier2/dossier3/fichier3.jpg
Remarquez que nous démarrons bien de la racine / (attention les symboles de séparation sont aussi des /)
Imaginons maintenant que le fichier fichier1.css fasse appel au fichier fichier3.jpg (comme un fichier HTML peut faire appel à un fichier CSS). Il est possible d'indiquer le chemin non pas depuis la racine, mais depuis le dossier (dossier2) qui accueille le fichier1.css, nous parlerons alors de chemin relatif :
dossier3/fichier3.jpg
Remarquez l’absence du / au début du chemin (c'est cela qui nous permettra de distinguer un chemin relatif et un chemin absolu).
Imaginons maintenant que nous désirions indiquer le chemin relatif du fichier fichier1.css depuis l'intérieur du dossier dossier4.
Comment faire ?
Il faut « remonter » d'un « niveau » dans l'arborescence pour se retrouver dans le dossier dossier2 et ainsi pouvoir repartir vers la bonne « branche ». Pour ce faire il faut utiliser 2 points : ..
../dossier2/fichier1.css
Il est tout à fait possible de remonter de plusieurs « crans » : ../../ depuis le dossier dossier4 permet de « retourner » à la racine.
Remarque : la façon d'écrire les chemins (avec des slash (/) comme séparateurs) est propre aux systèmes dits « UNIX », par exemple GNU/Linux ou encore Mac OS.
Sous Windows, ce n'est pas le slash qui est utilisé, mais l'antislash (\). Pour ce qui nous concerne ici, les chemins réseau (et donc le web), pas de problème, c'est le slash qui est utilisé.
Le contenu du fichier "fichier7.odp" utilise le fichier "fichier5.svg" :
Revenons sur l'adresse qui s'affiche dans la barre d'adresse d'un navigateur web et plus précisément sur le début de cette adresse c'est-à-dire le "http".
Selon les cas, cette adresse commencera par http ou https (nous verrons ce deuxième cas à la fin de cette activité).
Le protocole (pour rappel : ensemble de règles qui permettent à 2 ordinateurs de communiquer ensemble) HTTP (HyperText Transfert Protocol) va permettre au client d'effectuer des requêtes à destination d'un serveur web. En retour, le serveur web va envoyer une réponse.
Voici une version simplifiée de la composition d'une requête HTTP (client vers serveur) :
Certaines de ces lignes sont optionnelles.
Voici un exemple de requête HTTP :
GET /mondossier/monFichier.html HTTP/1.1
User-Agent : Mozilla/5.0
Accept : text/htmlNous avons ici plusieurs informations :
Revenons sur la méthode employée :
Une requête HTTP utilise une méthode (c'est une commande qui demande au serveur d'effectuer une certaine action). Voici la liste des méthodes disponibles :
GET, HEAD, POST, OPTIONS, CONNECT, TRACE, PUT, PATCH, DELETE
Détaillons 4 de ces méthodes :
GET : C'est la méthode la plus courante pour demander une ressource. Elle est sans effet sur la ressource.
POST : Cette méthode est utilisée pour soumettre des données en vue d'un traitement (côté serveur). Typiquement c'est la méthode employée lorsque l'on envoie au serveur les données issues d'un formulaire.
DELETE : Cette méthode permet de supprimer une ressource sur le serveur.
PUT : Cette méthode permet de modifier une ressource sur le serveur
Réponse du serveur à une requête HTTP
Une fois la requête reçue, le serveur va renvoyer une réponse, voici un exemple de réponse du serveur :
HTTP/1.1 200 OK
Date: Thu, 15 feb 2019 12:02:32 GMT
Server: Apache/2.0.54 (Debian GNU/Linux) DAV/2 SVN/1.1.4
Connection: close
Transfer-Encoding: chunked
Content-Type: text/html; charset=ISO-8859-1
<!doctype html>
<html lang="fr">
<head>
<meta charset="utf-8">
<title>Voici mon site</title>
</head>
<body>
Bienvenue sur mon site !
</body>
</html> qui sera interprétée par le client sous la forme suivante : ![]()
Nous n'allons pas détailler cette réponse, voici quelques explications sur les éléments qui nous seront indispensables par la suite :
Commençons par la fin : le serveur renvoie du code HTML, une fois ce code reçu par le client, il est interprété par le navigateur qui affiche le résultat à l'écran. Cette partie correspond au corps de la réponse.
La 1ère ligne se nomme la ligne de statut :
HTTP/1.1 : version de HTTP utilisé par le serveur
200 : code indiquant que le document recherché par le client a bien été trouvé par le serveur. Il existe d'autres codes dont un que vous connaissez peut-être déjà : le code 404 (qui signifie «Le document recherché n'a pu être trouvé»).
Les 5 lignes suivantes constituent l'en-tête de la réponse, une ligne nous intéresse plus particulièrement :
Server: Apache/2.0.54 (Debian GNU/Linux) DAV/2 SVN/1.1.4Le serveur web qui a fourni la réponse http ci-dessus a comme système d'exploitation une distribution GNU/Linux nommée "Debian" (pour en savoir plus sur GNU/Linux, n'hésitez pas à faire vos propres recherches). "Apache" est le cœur du serveur web puisque c'est ce logiciel qui va gérer les requêtes http (recevoir les requêtes http en provenance des clients et renvoyer les réponses http). Il existe d'autres logiciels capables de gérer les requêtes HTTP (nginx, lighttpd...) mais, aux dernières nouvelles, Apache est toujours le plus populaire puisqu'il est installé sur environ la moitié des serveurs web mondiaux !
Le "HTTPS" est la version "sécurisée" du protocole HTTP. Par "sécurisé" en entend que les données sont chiffrées avant d'être transmises sur le réseau. Seul le possesseur de la clé de déchiffrement sera en mesure de lire les données transmises sur le réseau. D'un point vu strictement pratique il est nécessaire de bien vérifier que le protocole est bien utilisé (l'adresse commence par "https") avant de transmettre des données sensibles (coordonnées bancaires...). Si ce n'est pas le cas, passez votre chemin, car toute personne qui interceptera les paquets de données sera en mesure de lire vos données sensibles.
Régi par la licence Creative Commons: Licence d'attribution en partage identique 4.0